有以下三个部分决定了您可以并行创立多少个图块。CPU,RAM,临时磁盘大小。第一步是弄明确限制因素在系统上的哪个地位。在下面应用这些公式:
让我从第一个公式CPU开端解释每个公式及其目标。这个公式是您的核心加上您的线程除以二。这样做是因为Chia进行绘图的方法。Chia分为四个阶段。第1阶段和第3阶段通常耗时最长。为绘图仪设置线程时,这只会影响阶段1。阶段2、3和4均为单线程。因此,当绘图移出阶段1时,它将释放额外的线程,您可以将其用于新的绘图仪。CPU可能会被超额应用,这意味着您可以超过总线程数,这只会减慢一点速度。它不会使绘图仪崩溃。
RAM非常简略。通常,当应用两个线程时,RAM的最佳数量是3389。为了使数学更简略一点,我应用3400。这是每个绘图仪在其绘图过程中将应用的数量。四舍五入的原因是RAM不能像CPU一样被过度分配。如果您用完了RAM,它将导致绘图仪出错。
临时空间也很简略。每个绘图仪将应用256GB(也称为239GiB)作为临时空间。四舍五入的原因是因为过度分配临时空间有些艰苦。在2TB NVMe上,您可以做到11-12个绘图仪,就可以做到。要害是绘图仪之间的延迟。只能通过您自己的系统的重复实验才干断定该值。
让我们持续以我的系统为例。
我有我系统的号码。我系统中的限制因素是RAM。一次只能以最佳数量的RAM最多运行9台绘图仪。应用此公式时,将应用2个线程和3400 RAM作为绘图仪设置。这将为您供给开箱即用的系统的良好起点。接下来要弄明确的是Delay(也称为交错)。延迟取决于其自身的一系列问题:
绘图速度部分取决于您拥有的“临时空间”的类型。NVMe是最好的,其次是SAS和SATA SSD,HDD是最差的。接下来的信息与NVMe品牌有关。是的,您正在应用的NVMe的品牌和型号。大多数Chia人都知道在为Chia进行绘图时,NVMe的耐力很重要,TBW(书面的TeraBytes)。人们没有意识到的是NVMe驱动器的持续写入性能。这通常不在NVMe的规格中,因为消费者的NVMe并未真正按照Chia应用它们的方法应用。某些NVMe驱动器具有SLC缓存供给包装盒上印有的高性能编号。在许多工作负载中,这很好。对于Chia来说,这不是一个好功效。一旦SLC缓存已满,具有此缓存的NVMe驱动器就会失去很多性能。所有这些都归结为NVMe上的把持器。有些NVMe的把持器不错,有些则没有。以Adata XPG SX8200 Pro 2TB为例。它具有精彩的开箱即用性能,但请看一下其持续的写入性能(Tom’s Hardware的信用):
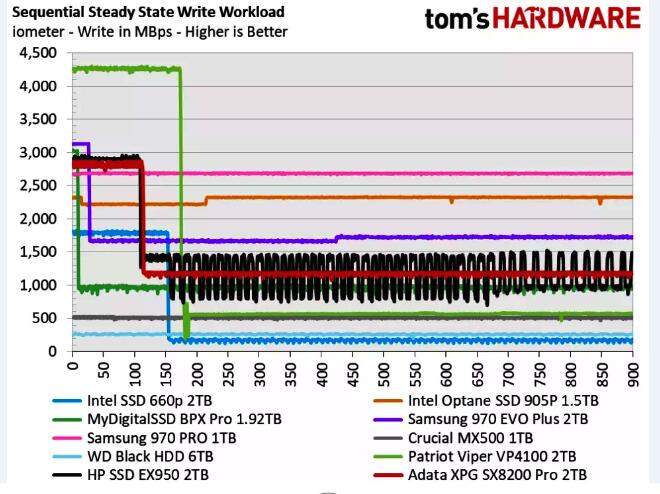
在图中,x轴是写入的数据总量。Adata是图中的红线。您可以看到,在写入大约120GB的数据之后,性能会大大降落。该图中的许多其他内容也是如此。写入175GB后,Patriot VP4100从4000+ MBps上升到500 MBps。这就是为啥有些人困惑于他们没有获得应有的性能。或者为啥第一轮比赛比第二轮要快得多。具有此功效的NVMe将无法通过Chia的方法供给最佳性能。每个绘图仪都写入1.4TB,仅生成一个绘图。如果并行处理的缓存很多,那么此缓存将很快被填满,第一阶段可能要消费数小时才干完成。
有了这些信息,您现在应当可以有一个很好的起点。现在,当您购置NVMe时,一定要考虑以下三点:容量,耐力,持续的写入性能。
我也想让您知道其他事情。绘图仪以前的版本中有很多旧数据,也会使新手扫兴。这不是故意的,只是Chia Client的更新频率如此之高,以至于很难更新每条旧信息。通常人们在不知道命令履行情况的情况下复制和粘贴命令,因此需要注意以下几点:
TikTok千粉账号购买:https://www.tiktokfensi.com/
 1对1专业客服
1对1专业客服 24小时服务支持
24小时服务支持 365天无间断服务
365天无间断服务 5分钟快速响应
5分钟快速响应
TOP