Chia绘图P盘优化技巧,不管有用没用都是建议!
结束并行思考
您一次拥有多少个图不应当是优化图时的重要考虑,而应当是在不增长图时间的情况下可以实现的最小偏移量。这里有2个优化设置和未优化设置的示例,我们稍后将介绍这些设置。
未优化

优化

硬件
所以首先我们需要懂得我们的硬件,您在这里有3个竞争的利益:SSD,RAM,CPU。让我们来看一下。
CPU:从中我们可以得到2个数据点,用于断定我们的最佳偏移量(我们的最大作业和我们的最大第1阶段作业)。对于总的最大作业数,我取总核心数(假设一个超线程CPU或任何AMD称之为AMD)减去一个。我创造阶段1:所有其他阶段的比率大约为0.4:1,这对于r = 4的磁芯来说是最佳的应用方法(以后我将在后面进一步研究r = 2)。
这对于r = 4产生以下成果(如果我在r = 2中再次尝试,但我首先需要更多的内存,将会更新)
4C / 8T-3个工作| 第1阶段中的1个(未测试)
6C / 12T-5个工作| 第1阶段2个(未测试)
8C / 16T-7个工作| 1阶段3(已测试)5800x(?45分钟为理想选择)
10C / 20T-9个工作| 1阶段3(未测试)12C / 24T-11个工作| 第1阶段4个(未测试)
16C / 32T-15个工作| 第一阶段6个(已测试)5950x(仍会在23至27分钟之间进行调剂)
固态硬盘:我创造这是情节时间的最大限制因素,最初我应用的是1枚sabrent火箭4.0 2tb,而您在上述时间看到的最大差距是一次涌现了7个情节和8个情节之间的差额。我建议为您拥有的每8个CPU核心推荐一个等效的驱动器,并且将来将在r = 2的情况下测试其中的4个。
Ram:对于r = 4情况,每个CPU内核4gb,这是最简略的一种(对于16C / 32T,为64gb …您明确了)
我们懂得了最大作业数和最大阶段1作业数,我们可以开端断定偏移量了。让我们以一个将为真或不为真的假设开端,但是这是一个起点,假设一个6小时的绘图时间。将6小时(360分钟)数除以您拥有的内核数,对于8个内核,这将是45分钟,这将是我们的起点。
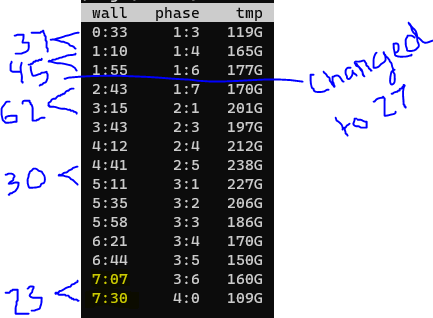
持续应用这些设置进行绘图,接下来将是一门艺术,但是基础上,您需要不断调剂偏移量,直到尽可能接近理想值为止。理想:前面讨论的最大绘图实际上是运动的,并且您的偏移量的定时已定为正好在绘图开端新的绘图时就开端了,如果偏移量太短,您会注意到直到最旧的几分钟后才开端绘图绘图完成,如果偏移量太长,则在某一点上将有少于然后处于运动状态的最大作业(这不必定是一件坏事,但这意味着您可以更快地绘图)
在这里,您可以看到工作上的调剂,我从23分钟开端,经过必定数量的工作后,时间变得很短,时间开端变长,直到62分钟,所以我改为27,现在将等候,看看是不是能奏效。(请注意:更改为27并没有影响,因为作业之间的时间仍然> 27分钟,这完成了23分钟的作业,而较长的延迟作业更加占主导地位,这导致所有作业之间相隔27分钟( (如果产生这种情况),那么下一个新作业也要相隔27分钟,这将是正确的偏移量。
重要是临时驱动器和crontab任务,用于主动传输到HDD。我在这里没有谈论登台驱动器,因为链接的线程对此有很好的领导。
您需要获得诸如plotman之类的东西,并且要在Linux中应用,这样的东西才实用
1.)如果您不应用Linux,则不认真看待它,挤出一些额外的绘图对您来说并不那么重要(这是好的,每个人都不需要那样)2.)Plotman容许您更改延迟和这种即时变更(即,下一个作业将具有新的延迟),这是必要的,并限制了阶段1中的作业数量。
应用此方法可以非常轻松地盘算绘图速度,只需将一天中的分钟数除以偏移量即可得到上述理想成果,然后将其乘以101.8。例如,如果您的理想偏移量是45:(1440/45)* 101.8 =每天3257.6GiB,则接近于8C cpu,32gb ram和1体面的2tb ssd可获得的偏移量。
5950x 64gb 3200MHz cl16(打算抛弃itx并转到128GB 3600)2x sabrent火箭4.0(还订购2个)2TB sata sssd进行升级(尺寸过大)
最新solo项目:1天1P云端方案,性价比高。云主机挖Chia币解决方案,p盘解决方案,一站式农场收割解决方案,详询在线QQ客服。
TikTok千粉账号购买:https://www.tiktokfensi.com/
 1对1专业客服
1对1专业客服 24小时服务支持
24小时服务支持 365天无间断服务
365天无间断服务 5分钟快速响应
5分钟快速响应
TOP